Microservices and the Ops / Dev ratio
The question about microservices is an ill-posed one. We really can’t discuss this without a definition of micro. The word micro means something to large organizations like Google or Netflix – roughly speaking, it is a size such that the company can parallelize the work of many engineers, by distributing services and their ownership to smaller teams.
In theory, by subdividing large services, resource contention and coordination friction can be removed. For example, instead of having a single point of contention (repo, branch, CI/CD, environment infrastructure) shared by 50 people with a single team leader, 7 teams of 7 people could be working in parallel, thanks to pre-negotiated APIs exposed by each microservice and light coordination across team leaders.
A team of 7 – a size well within the best practices – maintaining one service which is part of a larger product developed by 50 is hardly a controversial topic. Unfortunately, some less mature organizations haven't realized that they're not Google and think that having a team of 3 maintaining 7 microservices is an equally valid proposition. Spoiler alert: it isn't.
The benefit of breaking a service into smaller services is additional independence. The cost of doing so is extra work. Gains resulting from additional independence have to compensate for the extra work. But… this extra work isn't just extra work, is it? No! It is extra Ops work. Every time you subdivide a service you increase the Ops / Dev ratio. And that itself is a problem.

First, the original Devops culture is dead and buried. Nowadays, we often find “dev” “ops” that are actually “ops done by developers” or “snowflakes hanging in the cloud”. Second, even if this wasn't the case, only 10% of the Stack Overflow survey participants identify as Devops specialists and only 8.62% identify as Cloud infrastructure engineers.
This seriously complicates the math: not only gains resulting from additional independence have to compensate for the extra work, they now have to compensate for the extra cost of that work as a consequence of resource scarcity or, alternatively, for the low quality of such work if done by non-specialists. In organizations that aren't Google, the latter is more likely than the former.
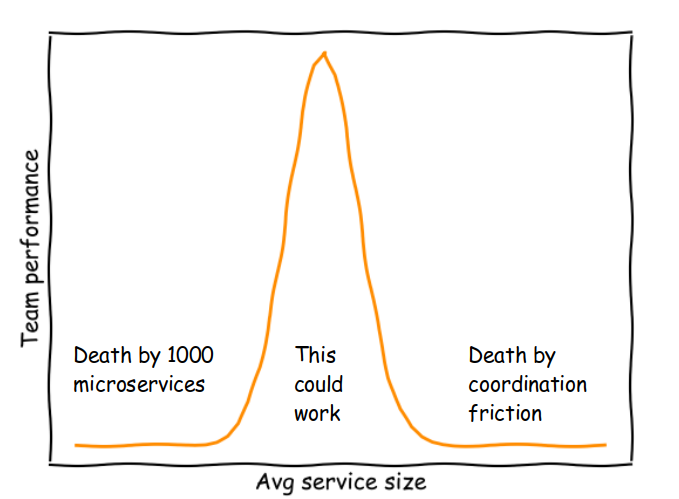
Since time is finite, the more we divide services, the more Ops we have compared to Dev: more network calls, more API backends requiring infrastructure, more databases, more CI/CD pipelines, more places where unique security patching procedures need to be applied and more sets of dependencies that might break upon updates. In general, we have more points of failure and likely more dollars spent on the cloud bill.
This means that we should be careful before hopping on the microservices Hype Train. Do we need a rigorous definition of micro to get rid of the ambiguity?
Here goes a candidate definition:
micro is a size such that the benefit of decreased resource contention and coordination friction, compared to those of a monolithic project, compensates for the increase in the Ops / Dev ratio and the consequential extra work and risk, taking into account the current state of the Devops culture, the scarcity of qualified Ops staff and the risk of business discontinuities stemming from additional points of failure.
It certainly looks like a complex optimization problem more than a subject to have simplistic views about. If you are Google, Netflix or a smaller but data driven organization you can probably come up with a mathematical model to calculate micro from the above definition. If you are unable to do so, you probably needn't worry about all this and should simply try to keep your Ops / Dev ratio as low as possible. Keeping your teams within the recommended size and assigning less than two services per team is likely a good rule of thumb.
Interesting related texts: