The Linux load average
What is the Linux load average?
This is not exactly an orphan question but, as with other questions addressed in the blog, it is surrounded by confusion. I will try to provide an explanation that is "as simple as possible, but not simpler", and also short enough to be worth reading.
Context
We sometimes see the load average values of a system in the output of the uptime command or by inspecting /proc/loadavg:
We often see plots of load average values inside monitoring systems:
This post will provide meaning to the previous pictures.
Definition 1
We will define the instantaneous load of a system as the number of tasks - processes and threads - that are willing to run at a given time t.
Willing to run tasks are tasks in states R or D. That is, they are either actually running or blocked on some resource (CPU, I/O, ...) waiting for an opportunity to run. The instantaneous number of such tasks can be determined using the ps command:
ps -eL h -o state | egrep "R|D" | wc -l
To be clear: tasks that want to run but are waiting for a CPU core to be available, or waiting for data from the disks / network, also count as instantaneous load.
(see footnote [1] for more info on this)
Definition 2
We will define the load average of a system as a specific averaging function of the instantaneous load value and the history of previous values. For Linux systems in particular, the recursive weighted average is:
\( a_t= Ca_{t-1} + (1- C)l_t \)
where
\( C = e^{-5/60A} \)
In the previous expressions, lt is the instantaneous load, from definition 1, and parameter A takes the values of 1, 5 and 15. The three sequences, corresponding to the three possible values of A, are called the 1m, 5m and 15m load average, respectively.
For A=0 we would find:
\( a_t = l_t \)
therefore, recovering definition 1 - the 0m load average is simply the instantaneous load.
Historically, load average values were calculated by the kernel every 5 seconds. In current kernels, there are some nuances related to sampling, but there has been no conceptual change.
Discussion
First of all, we should highlight that the load average from definition 2 is just a generalization of definition 1.
While their values are similar in nature, the higher the value of A, the lower the contribution of the instantaneous load compared to the contribution of the historic load average value. The main purpose of using an "averaging" function is the smoothing of fast oscillations which could render human inspection of load values almost impossible. The timespan of that smoothing effect is influenced by parameter A. In mathematical terms, at applies Exponential smoothing to lt.
The recursive sequence for at is simple but its ultimate meaning might not be evident at first glance. With a bit of work, we can turn it into an explicit sequence:
\( a_t= C^t a_{0} + (1-C)\sum\limits_{j = 0}^{t-1} C^j l_{t-j} \)
Since, by definition, a0=l0 we get:
\( a_t= C^t l_{0} + (1-C)\sum\limits_{j = 0}^{t-1} C^j l_{t-j} \)
which could also be expressed as:
\( a_t= C^t l_{0} + (1-C)\sum\limits_{j = 1}^{t-1} C^j l_{t-j} + (1-C)l_t \)
Let's break down this sequence made up of three terms:
- the initial instantaneous load value multiplied by a coefficient that decays to exponentially to zero; this term disappears quickly as time progresses
- all other past instantaneous load values multiplied by coefficients that make them exponentially unimportant, as their index t-j moves from the present moment to the past
- the current load value multiplied by (1-C)
Since the first term decays quickly, so as to study the relevance of past instantaneous load values we must focus on the second term.
We should first notice that the sequence of coefficients:
\( C^1, C^2, ... C^{t-1} \)
is a geometric progression and thus decays at a fixed fraction with each iteration.
Now let's suppose we want to check how many iterations it takes for this sequence of coefficients to decay from C to C divided by a constant k. If we write:
\( C^j = C/k \)
we will find:
\( j-1 = - {{ln(k)} \over {ln(C)}} \)
where j-1 is the number of iterations connecting j sampling moments. Given that there are 5 seconds between samples, this is equivalent to saying:
\( t_{1/k} = - 5 {{ln(k)} \over {ln(C)}} \)
If we now insert the definition of C, we get:
\( t_{1/k} = ln(k) 60A \)
Finally, by setting k=e we obtain:
\( t_{1/e} = 60A \)
We can now tell that the Xm load average is the instantaneous load exponentially smoothed in such a way that the importance of the coefficients applied to the historical load values decreases to 1/e in X minutes. The mysterious coefficients at the definition of at are now explained!
Because e =~ 2.7, a reduction to 1/e of the initial value is a reduction of approximately 63%. We can also easily tell that a reduction of 95% happens in 3, 15 and 45 minutes for the 1m, 5m and 15m load averages, respectively.
The Linux kernel provides these three distinct load averages so that users can analyze how the system responds to sudden changes in instantaneous load at different timescales. All of them converge to the instantaneous load value - at different rates - if it stabilizes. Which of these sequences is most useful depends on the practical situation.
Let's try a hands-on exercise.
The load average can be calculated with a simple bash script, using definitions 1 and 2, just as the Linux kernel does (see kernel source). Here is the example output of one such calculation that estimates the 1m load average and compares it to the calculation performed by the Linux kernel:
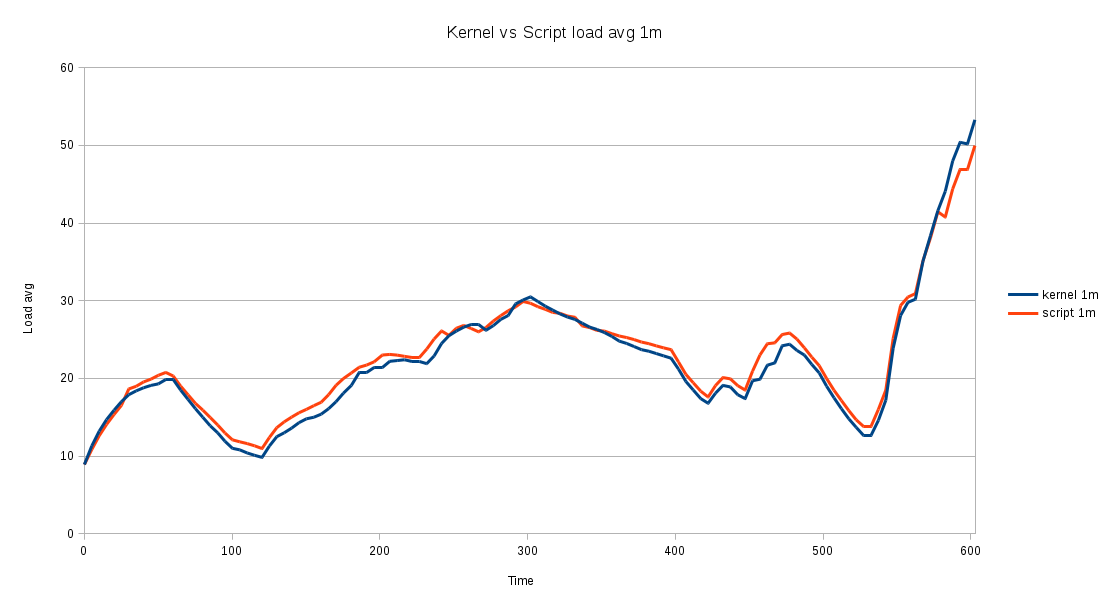
This result confirms that definitions 1 and 2 are correct, as the difference between the script-based calculation and the kernel calculation is negligible.
The same script also allows us to evaluate the different load metrics on a real system that is initially running on a "baseline load with fluctuations" regime, then stress tested for 5.5 minutes, and later returned to its initial state:
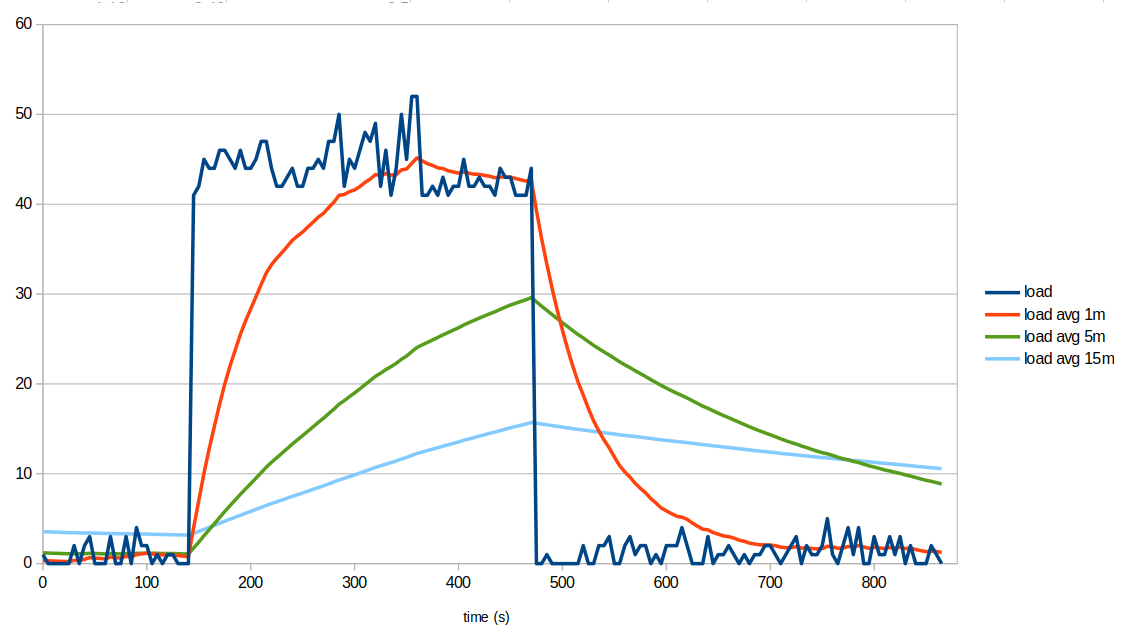
We can clearly see that load average metrics smooth short-lived fluctuations (multiple cycles per minute). They're also slow in response to transitions between sustained load regimes. In our example, the baseline load was elevated for about 5.5 minutes, and only the 1m load average had enough time to converge to the higher instantaneous load and then return to the baseline. It took roughly three minutes for the 1m load to reach a new level in either direction, while the 5m and 15m load averages mostly produced intermediate values because the pulse was short relative to their smoothing windows.
If the higher-load pulse had been shorter, none of the load averages would have moved much. In practice, load averages are useful for showing load patterns on timescales of minutes - faster variations are strongly attenuated and very short pulses are mostly smoothed out.
Now that frequencies have been dealt with, let's go back to load values. We now need to argue that there is no such thing as too high a load average in absolute terms. Well, the number of tasks that are willing to run on a given system depends on:
- the architecture of the running software (is it mostly monolithic? or prone to spawn many processes? how interdependent are these processes?)
- the CPU throughput requested by the running software
- the I/O throughput requested by the running software
- the CPU performance of that system
- the I/O performance of that system
- the number of available cores
Therefore, we can only say "the load average is too high on that system" if we know the "normal value for that system". The "normal value" is an empirically found value under which that system usually runs and is known to perform acceptably. The normal value could well be 2 for a server with a low number of cores that runs an interactive web application, or it could be 50 for a server that runs (non-interactive) numeric simulations jobs overnight.
Furthermore...
-
for the same requested I/O effort and the same hardware, a software implementation that spreads computation across many processes or threads will generate a higher load average; even though the actual throughput is the same, 10 processes trying to write 10MB each on an I/O starved system generate a higher load average than one process trying to write 100MB on the same system.
-
given a certain software program that sets all the existing CPU cores to 100% while running on a specific machine, its execution on a system with a lower core count, or slower cores, will generate a higher load average; whether that higher load is a problem or not depends on the use case (if your numeric simulation or your file server backup takes 10 more minutes during the night, but is ready and able in the morning, then no harm done).
Load average vs CPU usage
As we've seen so far, load average values don't have an absolute numerical meaning unlike CPU usage values, which are expressed in % of CPU time:
- %usr - time spent running non-kernel code. (user time, including nice time)
- %sys - time spent running kernel code. (system time)
- %wait - time spent waiting for I/O.
- %idle - time spent idle.
Note: %wait is not an indication of the amount of I/O going on - it's an indication of the extra %usr time that the system would show if I/O transfers weren't delaying code execution.
For systems running below their limits, CPU usage values are much more useful than load average values, as their numeric interpretation is universal. But once limits are hit, i.e., CPU %idle time is nearly zero, load average values allow us to see how off limits the system is running... once we establish a baseline, which is the normal load average for that system (software+hardware combination).
Summary of true statements
-
If all system cores are running at
%sys+%usr=100, the instantaneous load is equal to or higher than the number of cores. -
The instantaneous load being higher than the number of cores doesn't mean all cores are running at
%sys+%usr=100, since many processes may be I/O waiting (state D). -
The instantaneous load being higher than the number of cores implies that the system can't be mostly idle; at least some of the cores will be seen in sys, usr or wait states for significant amounts of time.
-
A system can be slow/unresponsive even with an instantaneous load below the number of cores because a small number of I/O intensive processes may become a bottleneck.
-
In a pure CPU intensive scenario (negligible I/O, no processes in state D) where %idle > 0, the instantaneous load is equal to
((100 - %idle)/100) * NCORES; for instance, on a 4 core system at steady%sys+%usr=90, we would have an instant load of((100-10)/100)*4 = 3.6.
Statement 5 can be easily tested by running:
stress -c X
while looking at the output of top on a different terminal, waiting for the 1m load average to stabilize. It is trivial to see that the above formula holds up to X=NCORES, which will cause %idle=0.
Note on Hyperthreading: We haven't discussed Hyperthreading, or the equivalent AMD feature, to avoid further complicating the discussion, but where above we say NCORES, it could be the number of virtual CPUs, including CPU threads. Of course, each additional % usage on the second thread of an already busy core doesn't yield a proportional throughput.
Footnotes
[1] - The same result should be obtainable by parsing /proc/loadavg (4th field) or /proc/stat (procs_running, procs_blocked). What I've seen from experience is that multiple processes in state D are shown by ps but not counted on /proc/loadavg, and neither /proc/loadavg (4th field) nor /proc/stat include threads in the task counters, even though they're taken into account in the load average numbers shown by the kernel.
References
The load average bible in three volumes: